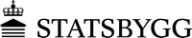I fjor ble det generert 1,8 billioner gigabyte - eller 1,8 zettabyte - med data i det digitale univers.
Og mer skal det bli:
Analyseslskapet IDC peker på at dataene vi tar vare på vil femtidoble seg de neste ti årene.
Myndigheters krav til dokumentasjon og nye regler er en viktig drivkraft i dette markedet. Det samme er et raskt økende antall bilder og videoer i stadig høyere oppløsning.
Veksten har fortsatt uforminsket i svært mange år.
Det typiske bildet er at ingenting slettes. Det aller meste av det vi har produsert de siste årene er tilgjengelig online på en eller annen måte, og det ligger dessuten gjerne i mange kopier på et eller annet backup-medium, selv om dataene ikke har vært i bruk på veldig lang tid.
Les også: Spår harddisker på 150 TB
Lagring i lag
Etter hvert som datalagrene er blitt større, har man innsett at alt ikke trenger å lagres i det samme høyytelseslageret. Det blir for dyrt.
I praksis er en fil etterspurt i noen dager etter at den er skapt og så er det ingen som spør etter den mer.
Løsningen er det man kaller tiering, eller oppdeling i lag etter hastighet.

Der det er stor omsetning av data, bør det gå fort. Derfor lagres slike i et lynraskt lager, gjerne basert på SSD-disker og støttet av et stort hurtiglager i RAM.
Når dataene ikke lenger er så etterspurt, flyttes de ned på raske harddisker som spinner fortere enn vanlige og er koblet til på en raskere måte.
Til slutt blir de digitale verdiene dumpet over på det tregeste lageret basert på den samme diskteknologien som sitter i pc-er. Slike lager består av store, relativt trege, men billige Sata-disker.
Skulle noen etterspørre en fil herfra, er den eneste ulempen at det tar litt lengre tid. I verste fall er disken stanset for å spare strøm, og da må den spinnes opp i noen sekunder før filen kan overføres.
Ofte er det lurt å bruke det tregeste lageret som et arkivsystem. Hit flyttes lite etterspurte data fra primærlageret. I slike arkiver lages det en indeks som kan søkes gjennom et webgrensesnitt. Resultatet er at det dyre primærlageret vokser lite, mens stadig mer havner i det billige arkivet.
Les også: Ny superdisk om to år
Virtualisering
Ytterligere en måte å effektivisere lagring på er virtualisering.

.jpg)
I et virtuelt datalager er det virtualiseringsprogrammet som bestemmer hvor dataene befinner seg.
Brukerne ser lagrene slik de ønsker og kan forholde seg til det. Dette er både forenklende og kan gjøre det mulig å utnytte gammelt utsyr på en nye måte.
Dessuten er det slik at man i virtuelle miljøer typisk har veldig mange likt konfigurerte maskiner.
Derfor kan virtualisering kombinert med lagring som støtter deduplisering spare opp til 90 prosent av lagringsplassen.
Komprimering
En enkel metode for å få mer data inn i et lager er å komprimere dataene når de legges inn og dekomprimere dem når de hentes ut.
Avhengig av hvilke data det er snakk om, kan kompresjon gi store effekter.
Et digitalt bilde lar seg nesten ikke komprimere, mens mange typer filer gjerne kan komprimeres med 50 prosent eller mye mer. Ulempen med kompresjon er at det tar tid og ressurser å pakke filer opp og ned.
Derfor brukes kompresjon sjelden på primærlagring hvor ytelse er svært viktig.
Dedublisering
En annen plasstyv er dubletter.
En dublett kan være så mangt, fra et morsomt bilde som har gått på e-post til alle ansatte, og som derfor kan bli lagret og sikkerhetskopiert i et stort antall eksemplarer til små blokker inne i ulike filer på 4000 tegn som er like.
Kan man dedublisere, eller dedupe som det heter på fagsjargong, kan man redusere datalagre med mellom 50 og 90 prosent.
Jo større datamengder det er snakk om, jo større er effekten. I stedet for å skrive filen eller blokken flere ganger lagres en peker til den ene man lagrer.
Les også: Hvilken ultrabook skal jeg velge?
Tynn tildeling
En annen faktor som har gjort datalagring kostbar er hvordan slike lagre tradisjonelt har blitt fordelt.
Når en bruker har bedt om å få et lager på 500 GB, har vedkommende fått det. Problemet er at brukeren ofte ikke trenger denne lagringsmengden med en gang, men vil vokse inn i den over tid.
Slikt blir det gjerne 1 TB av, fordi slike lagre typisk også skal sikkerhetsspeiles. I de siste årene har man utviklet mer intelligent programvare for å administrere slike lagre og innført det som kalles thin provisioning, eller tynn tildeling på norsk.
Når det benyttes, vil brukeren se den lagerstørrelsen man er litt enige om – 500 GB. Men i virkeligheten er ikke lageret mye større enn det som benyttes i starten, f. eks 20 GB.
Uten tynn tildeling hadde resten vært reservert og stått ubrukt, men så fikser administrasjonssystemet dette og øker plassen opptil 500 GB etter behov. I praksis kan dette spare over 50 prosent av planlagt lagringsplass.
Les også:
Berøring, bevegelighet og alt-i-ett
Fjerner forsinkelser på nettetSuperdatakraft gir digital krystallkule