
Semantiske Dager
Deltakere: 185
W3C-medlemmer: Computas, Fast og Opera
Aktuelt fordi: Norge er langt fremme på semantisk web
To varianter
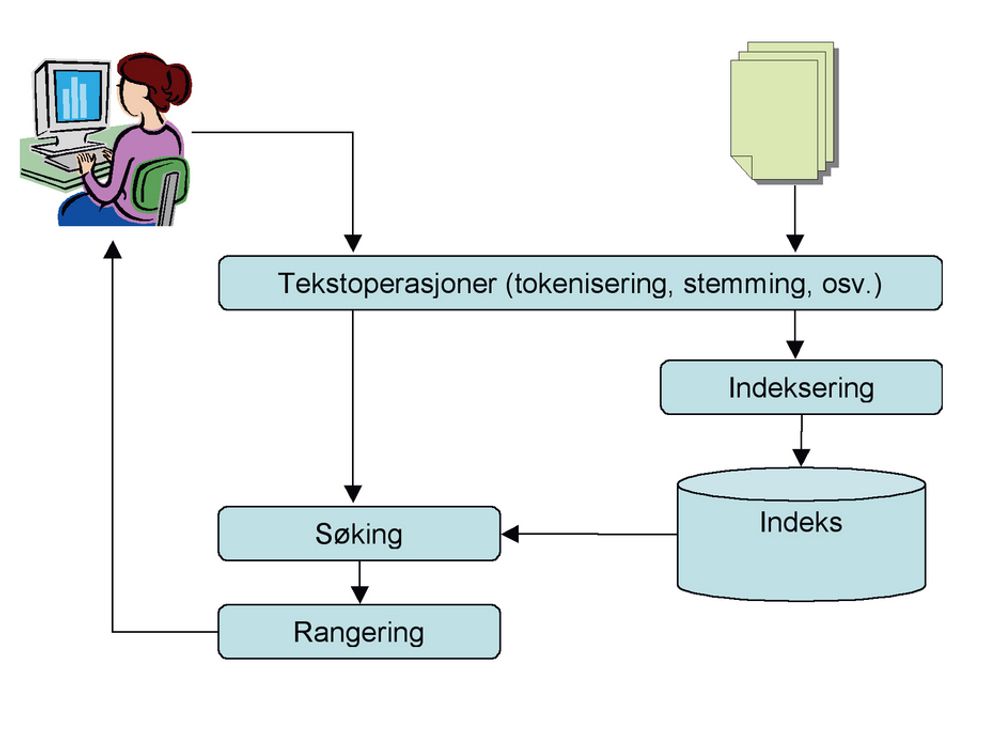
Tradisjonelt søk.Tradisjonelle søkesystemer som for eksempel Google, Yahoo og Fast er basert på det vi kaller vektorrommodellen og telling av ordfrekvenser i dokumenter. Hvert dokument beskrives av en vektor av ord. En vekt for hvert ord i vektoren sier hvor viktig dette ordet er i dokumentet.
Et ord som forekommer ofte i dokumentet eller står på en prominent plass, som for eksempel i tittelen, gis en høyere vekt enn andre ord.
Når brukeren søker etter noe, konstrueres en tilsvarende vektor for spørringen. Man sammenlikner spørrevektoren med alle dokumentvektorene i systemet og rangerer dokumentene på bakgrunn av likhet med spørrevektoren
Problemet med denne tilnærmingen er at man ikke har noen formening av hva ordene står for. Man ser ikke at «bil» og «biler» er bøyingsformer av det samme ordet, eller at «automobil» og «bil» står for det samme.
Noen systemer har delvis løst dette problemet ved å ta i bruk stemming eller lemmatisering. Ved stemming erstatter man den bøyde formen med stammen i ordet, for eksempel «biler» med «bil» og «skrive» med «skriv».
Ved lemmatisering erstatter man den bøyde formen med oppslagsformen, noe som gir nesten det samme resultatet som stemming.
Dette gjør at vi kan håndtere variasjon i skrivemåten av et ord, men vi vet fortsatt ikke hva ordene står for. Vi vet fortsatt ikke at «automobil» og «bil» har samme betydning eller at «folkevogn» og «boble» i visse situasjoner brukes om hverandre. Vi kan heller ikke vite at en bruker som søker etter «tyske biler» kan være interessert i dokumenter om Mercedes, BMW, VW og Porsche.
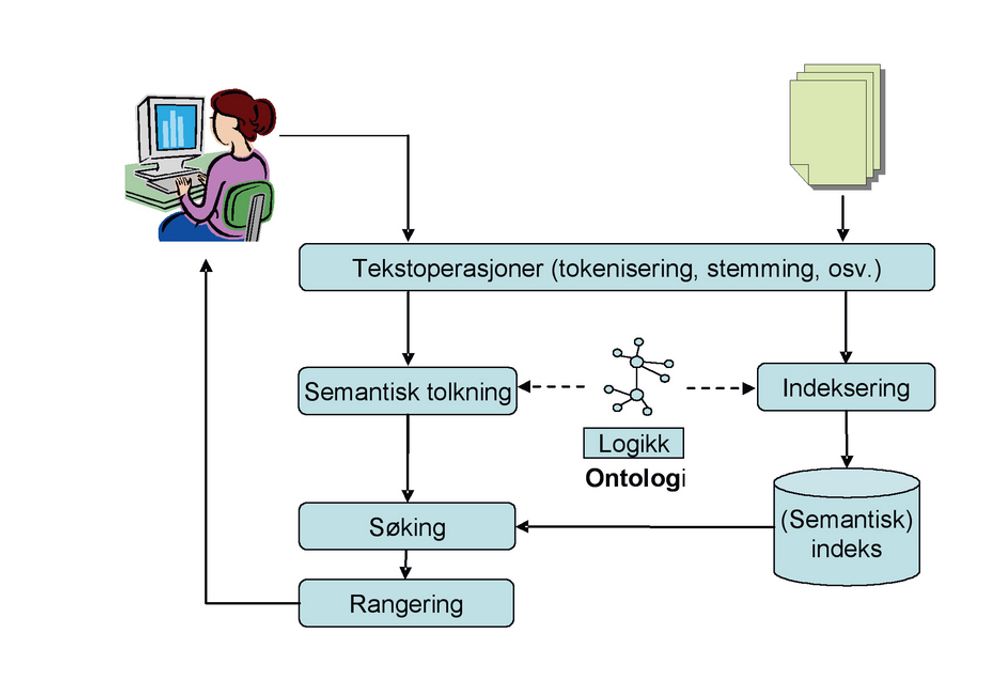
Semantisk søk. I søk som benytter semantisk tolkning, kommer begrepet ontologi inn. En ontologi er en eksplisitt spesifikasjon av et domenes viktigste konsepter og deres egenskaper og relasjoner. Den forteller oss hva domenet er for noe, og hva slags begreper som brukes til å beskrive ting i domenet.
En bilontologi vil for eksempel si at «automobil» og «bil» er synonymer, og at «boble» brukes om en spesiell type VW-biler. Den vil spesifisere at sportsbiler og SUV-er er spesialiseringer av bil, og at en bil inneholder et ratt, fire hjul, osv. Et annet sentralt punkt er at ontologier defineres formelt og tillater maskinell resonnering.
Tanken i ontologisk drevet søk er å gjenfinne dokumenter basert på semantisk innhold. I prinsippet er det to måter å gjøre dette på.
Den første er ved semantiske indekser. Man kan semantisk annotere alle dokumentene i systemet og bruke disse til å lage en semantisk indeks. Disse annoteringene består av ontologiske konsepter og relasjoner som gir et sammendrag av dokumentets innhold.
Når brukeren spør etter dokumenter, oversettes brukerens spørring til ontologiske konsepter, og selve søkeprosessen blir å matche denne mot de semantiske indeksene i systemet.
Et dokument som handler om biler, vil ha konseptet BIL i sin semantiske indeks. En spørring om automobiler konverteres til en semantisk struktur som også inneholder BIL. Slik kan man finne alle dokumenter som handler om biler uavhengig av hvordan hvilke ord som brukes i dokumentene.
Den andre er semantisk mapping av spørring. Her prøver man å tolke brukerens spørring semantisk ved å sammenlikne termene i spørringen med elementer i ontologien. Ontologien utvides med mekanismer for å mappe konsepter og relasjoner til de ordene som faktisk brukes for disse konseptene i dokumentsamlingen.
En slik mapping vil for eksempel si at konseptet BIL i dokumentsamlingen refereres til som bil, bilen, biler, automobil, osv.
I tillegg kan man bruke ontologiske relasjoner til å forbedre spørringen eller hjelpe brukeren til å formulere relaterte oppfølgingsspørsmål. Et søk på tyske biler kan for eksempel utvides til å inkludere navn på tyske bilmerker hvis søkesystemet tror det kan gi bedre resultater for brukeren.
Det har vært sagt og skrevet mye om semantisk web også tidligere, men oppmerksomheten rundt begrepet er sterkt økende, også i Norge.
Konferansen Semantiske Dager i Stavanger tidligere i vår samlet 185 deltakere, hvorav over halvparten fra oljeindustrien.
Men også IT-industrien var godt representert, og noe av formålet med konferansen var nettopp å tydeliggjøre de mulighetene utviklingen av semantisk teknologi gir for etablering av norsk kunnskapsindustri.
Presis informasjon
Utviklingen av Internett har på få år flyttet oppmerksomheten fra å fremskaffe data i store mengder til å få ut presis og pålitelig informasjon.
Dette gjøres med basis i semantikken - læren om mening i språket. På denne måten kan man skape mer orden i informasjonskaoset.
Her kommer begrepet semantisk web inn i bildet. World Wide Web Consortium (W3C), den organisasjonen som definerer og overvåker de standardene weben hviler på, har definert de semantiske språkene RDF (Resource Description Framework) og OWL (Web Ontology Language) som muliggjør presise beskrivelser av data, både på Internett og i andre IT-systemer.
Et stort anvendelsesområde av semantisk web er rask og riktig formidling av informasjon mellom personer og IT-systemer som mangler felles begrepsapparat. Det kan gjelde alt fra enkel konvertering av skjemaer til kompleks samordning av beslutninger.

Et annet område med stort potensial er effektiv støtte for kontinuerlig innhenting, bearbeiding og formidling av kunnskap. Evnen til å lære og å videreutvikle kunnskap er en avgjørende konkurransefaktor i de fleste virksomheter. Semantisk teknologi kan gi et fundamentalt nytt bidrag til bedre forvaltning av kunnskap, fordi denne teknologien forstår meningsinnholdet av det som læres.
Norge i front
Under konferansen i Stavanger hadde arrangørene hentet inn guruen Eric Miller som foredragsholder. Han er professor ved Massachusetts Institute of Technology og leder arbeidet med semantisk web i W3C.
Han poengterte at standarder og verktøy etter hvert kommer på plass, blant annet støtter Oracle siste versjon RDF. Han fortalte også om en kraftig økende industriell bruk av semantisk web, både ute på den offentlige weben og internt i bedrifter. I USA er farmasiindustrien ledende på dette området ved siden av offentlige etater, som for eksempel forsvaret.
Miller, og også flere av de andre utenlandske foredragsholderne på seminaret i Stavanger, var imponert over det som ble presentert fra norsk side, kanskje spesielt arbeidet som gjøres i regi av Oljeindustrien Landsforening (OLF). Han mente at norske kunnskapsbedrifter, med basis i tradisjonell industri, er godt posisjonert til å ta deler av et hurtig voksende internasjonalt marked.


Computas med i W3C
Computas er nylig tatt opp som medlem i W3C. – Det er spesielt organisasjonens utvikling av semantisk web som er bakgrunnen for vårt ønske om å innta en mer aktiv rolle, sier direktør Roar Fjellheim, som også var nestleder for arrangementet i Stavanger.
Computas er sammen med Statoil og andre partnere engasjert i utvikling av et system for kunnskapsforvalting i oljeboring (AKSIO) basert på semantisk web.
- Vi har et meget sterkt fundament i kunnskapsbaserte systemer, og semantisk web er for oss et naturlig steg, sier Fjellheim. - Gjennom medlemskapet i W3C får vi mulighet for å påvirke utviklingen av neste generasjons åpne web-standarder for semantikk (RDF og OWL).
Andre W3C-medlemmer i Norge er Fast Search & Transfer og Opera.




