
Denne uken la utviklere i Google frem deres siste fremskritt innenfor bildegjenkjenning. Googles systemer kan nå beskrive i fullstendige setninger hva som foregår på bilder. Tidligere har selskapet vist hvordan deres systemer kan identifisere enkelte objekter i bilder, som for eksempel katter i Youtube-videoer.
Men aldri før har de klart å formulere seg i fullstendige setninger, og i tillegg beskrevet hvilke handlinger som foregår.
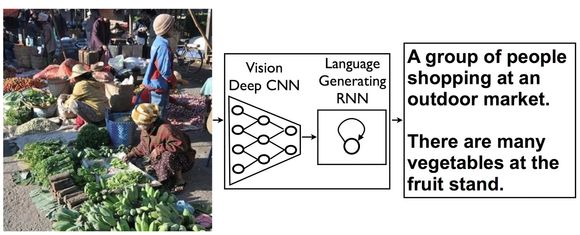
I sitt nye prosjekt har Google satt sammen to ulike systemer som nå har begynt å snakke med hverandre. Det ene er et system som matematisk gjengir hva som finnes i et bilde, og det andre er et system som genererer fullstendige setninger. Det siste som en del av selskapets automatiserte oversetting.
Les også: Snart skal det mer til for å knuse skjermen
Etterligner hjernen
Professor ved Universitetet i Oslo, Jim Tørresen, har skrevet bok om kunstig intelligens og jobber til daglig i forskningsgruppen «Robotikk og intelligente system». Han sier koblingen av disse to systemene er noe av nyvinningen her.
– Dette er en kombinasjon av to fagfelt som har eksistert lenge, datasyn og språkteknologi. Det første går på deteksjon og gjenkjenning av objekter i bilder, og det andre går på blant annet bruk av naturlige språk i brukergrensesnitt i datamaskiner. Vi har til nå blitt vant til muligheten mobilkamera har til å gjenkjenne ansikter i bildet og også gjenkjenne hvem som er på bildet. Nå tas dette hakket videre ved at andre objekter enn ansikter kan gjenkjennes og ikke bare listes opp, men det kan uttrykkes hva som skjer i et bilde, sier han.
Utviklerne har ikke laget et ferdigdesignet system for å forstå bilder. I stedet lærer systemet seg selv hva som er innholdet i bildet.
– Det er en modell som etterligner funksjonen i vår egen hjerne og hvordan syn-stimulanser på netthinnen blir tolket gjennom en rekke lag av hjerneceller som kalles nevroner. Styrken i koblingene mellom nevronene representerer det vi har lært, og derfor går læring i den kunstige modellen ut på å justere tilsvarende parametere i modellen, sier Tørresen.
Les også: Se video av monsterskipet som er på vei mot Norge
Lag av nevroner
Denne hjernetilnærmingen til datasystemer ble ifølge Technology Review påbegynt allerede på 50-tallet. Problemet den gang og i lang tid etter, var at det ikke fantes datamaskiner som var kraftige nok til å gjøre alle de nødvendige utregningene som krevdes for at systemet skulle lære nok.
Men nå har blant annet Google systemer som har kapasitet til å gjøre det.
Nevronnettverkene fungerer slik at et første lag av digitale nevroner identifiserer de mest grunnleggende delene av et bilde, som for eksempel en ende eller en kant. Systemene lærer seg å forstå dette ved at pikselkombinasjonen oppstår oftere enn det som ville vært tilfelle ved ren tilfeldighet.
Deretter forer dette laget informasjonen videre til neste nevronlag som oppdager en mer avansert form i bildet. Det kan være for eksempel et hjørne. Slik fortsetter det nedover i lagene inntil systemene klarer å plukke ut objekter og videre handlinger.
Vi er imidlertid ikke der at systemene klarer å finne ut helt selv hva som eksiterer ute i verden. Fortsatt må det få beskjed om hva det enkelte objekt faktisk er, før det kan beskrive det. I treningsfase fikk derfor systemet vite hvordan mennesker har beskrevet ulike bilder. I dette tilfellet ble det foret med flere titusener av bilder og beskrivelser.
Les også: Vingene på dette flyet kan forandre form i lufta
Kan hjelpe svaksynte
Etter treningsfasen ble nevronnettverkene sluppet løs på flere millioner bilder lastet opp på Flickr. Her fikk i systemet vite hvordan mennesker ville ha beskrevet innholdet, men resultatene var overraskende gode. På en nøyaktighetsskala fra 0 til 100, klarte systemet i overkant av 60. En lignende eksperiment ved Stanford University fikk nylig et resultat på mellom 40 og 50.
Når de samme resultatene ble testet på folk, var imidlertid poengsummen 2,5 på en skala fra én til fire. Det betyr at det fortsatt er en lang vei å gå før disse systemene kan gi pålitelige gjengivelser av virkeligheten. Men det er ikke lenger umulig å se for seg at kameraer plassert på offentlige steder for eksempel kan registrere handlinger som rapporteres videre.
Nyvinningen har åpenbare muligheter for bilde- og videotjenester som Youtube og Flickr, men kan også blir mer allment nyttige.
– Framfor å sende en melding til Facebook eller venner om hva som skjer rundt deg, kan systemet her fortelle det for deg. En mer nyttig anvendelse er kanskje som et hjelpemiddel for blinde og svaksynte som kan få en kunstig ledsager, sier Tørresen.
– Er dette kunstig intelligens?
– Ja, jeg vil si det, siden kunstig intelligens ofte beskrives som systemer som har evnen til å framvise en intelligent oppførsel i form av læring av eksempler og tilpasning mens det er i bruk. Vi snakker her samtidig langt i fra om intelligens på nivå med mennesker i form av hvor generelt gode vi er til å se hva som skjer rundt oss og også uttrykke det med ord, sier profesoren.
Les også:
Toyota: Mirai er framtidens bil

