
Kompresjon
1. Prediksjon
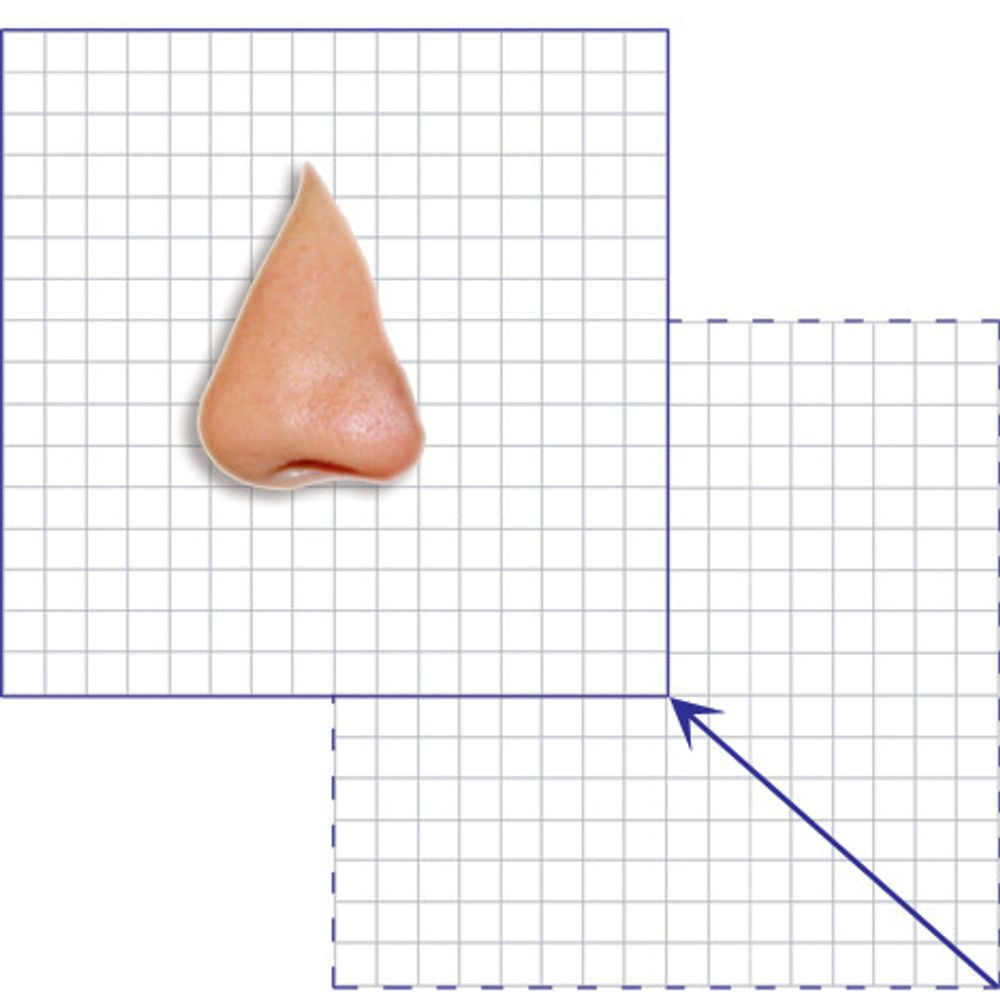
Ved å se på hvordan bevegelsene har vært i tidligere bilder, går det an å forutse hvordan neste bilde vil se ut. Prediksjonen tar utgangspunkt i såkalte makroblokker, som er en oppdeling av bildet i 16 X 16 piksler blokker.
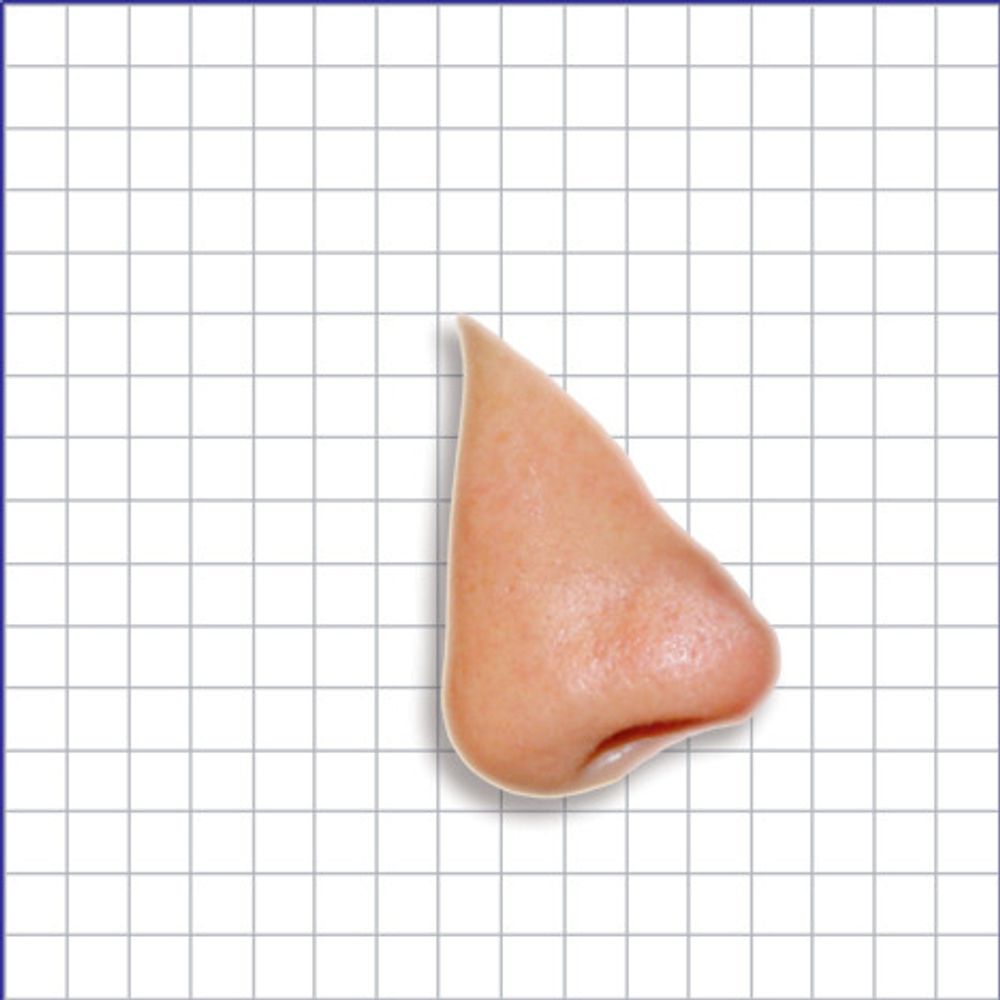
Poenget er å skape et uttrykk for bevegelsen i bildet og uttrykke den på vektorform (hvor blir det av nesa). Prediksjonen vil gi en første tilnærmelse til den bildeblokken (16x16 piksler) som skal beskrives, men i noen tilfeller vil dette være en fullgod beskrivelse. Dette skjer vanligvis når det ikke er noe bevegelse i bildet. I andre tilfeller må vi komplettere med et restsignal i tillegg til prediksjonen. Et eksempel her er at prediksjonen er en «kopi» av nesa fra forrige bilde. Men den er også dreid litt slik at vi må legge til litt ekstra informasjon for å få en helt riktig versjon av nesa i det nye bildet.
2.Transformasjon
En teknikk som kalles diskret cosinus transformasjon bruks for å behandle restsignalet. Poenget med transformasjonen er å samle kompleks informasjon på en måte som er enklere å behandle rent datateknisk. Resultatet av denne prosessen er et sett med koeffisienter.
3. Kvantisering
Kvantiseringen gjøres for å representere de transformerte koeffisientene på en mye grovere skala. Dette er det viktigste elementet i datakompresjonen, men det er også her tapene introduseres og som i varierende grad går ut over kvaliteten i forhold til originalen. Koderen velger kvantiseringsgraden dynamisk slik at den kan styre forholdet mellom bitforbruk og kvalitet. Denne dynamikken resulterer i at et bilde med lite bevegelse vil bli mye bedre enn et bilde med mye bevegelse. Enkelt fortalt resulterer kvantiseringen i at man overfører «små tall» i stedet for «store tall», og til dette trengs færre bit.
4. Koding
På dette trinnet består hovedelementene i datastrømmen av bevegelsesvektorene som prediksjonen skaper og de kvantiserte verdiene. Disse blir så statistisk kodet på en måte som gjør at de tar minst mulig plass, men uten å introdusere tap. Mpeg 4 kan bruke to forskjellige metoder her: En versjon som baserer seg på Huffmankoding eller en mer effektiv, men også mer regnekraftkrevende metode som benytter aritmetisk koding.
Derfor kompresjon
Uten kompresjon ville digital video i form av TV-kanaler eller DVD-filmer vært svært vanskelig. La oss se på et eksempel. I standard-TV er oppløsningen 720 ganger 576 punkter, og det er 50 halve bilder i sekundet. Halve på grunn av interlacing, eller linjefletting. Det gir 25 hele bilder i sekundet der hvert punkt har 12 bits fargeoppløsning som er tre Bytes. En film på to timer, eller 7200 sekunder består av 7200 X 720 X 576 x25 X 1,5 som er 111974400000 Bytes, eller ca. 112 GB. En DVD tar bare 9,4, og det skal inkludere plass til flerkanalslyd, ekstramateriale osv. Bare bilder i en TV-sending ville trenge ca 124 Mbit/s.
Når vi nå skal over til HD-TV, kan vi tre- til seksdoble disse tallene. Uten kompresjon ville vi neppe sett digital-TV på en lang stund.
Det går an å komprimere video fordi den inneholder redundans, både i tid og rom.
Elementer som går igjen mange ganger eller er svært like innenfor et bilde eller mellom bilder, trenger bare å beskrives detaljert en gang.


Kompresjonen innen det enkelte bilde er omtrent lik den vi kjenner fra stillbilder (JPEG) og kalles intraframe kompresjon. Kompresjonen mellom bildene kalles interframe kompresjon.
Jo mer bevegelse det er i videoen, desto vanskeligere er det å komprimere den mye uten at det går ut over kvaliteten. De som ser på satellitt-TV eller på kabel-TV (som tar ned de fleste kanalene fra satellitt), vil kjenne igjen dette som masse blokker, eller firkanter i bildet.
Mens lyd kan komprimeres rundt 10 til 1 uten spesielt hørbare effekter, kan video komprimeres mye mer. Uten synlig tap kan 20 til 1 oppnås, mens 100 til 1 kan nås med litt degradering.
Video fra komprimerte bilder
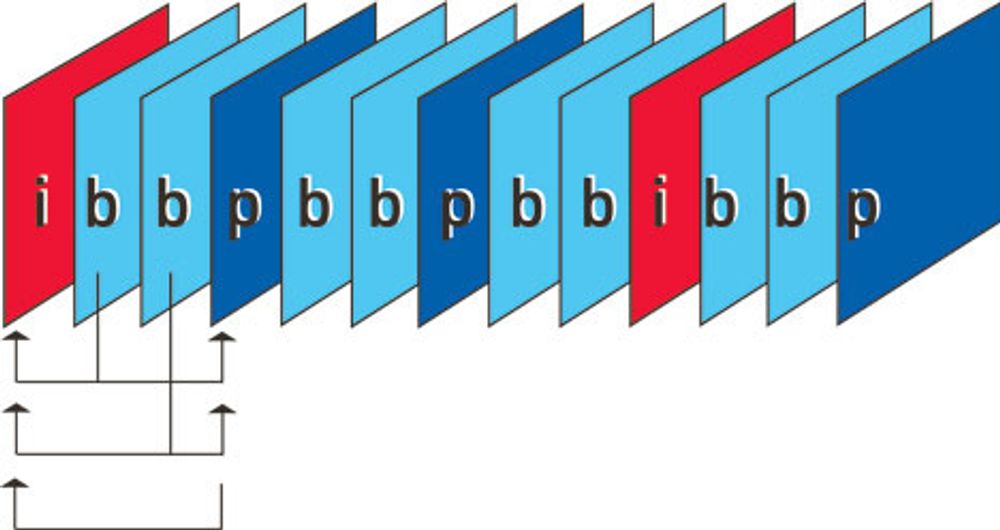
Starten på en komprimert video består av et I-bilde.
Det kodes omtrent som et JPEG-bilde vi kjenner fra digitale stillbilder, og det har ingen referanser til tidligere eller kommende bilder. Deretter følger B- og P-bilder. De inneholder bare endringer av bildeinformasjonen og ikke hele bildet. Et P-bilde inneholder referanse til tidligere I- eller P-bilder, mens B-bilder kan referere til både tidligere og påfølgende I- og P-bilder.
I-bildene trengs for å skape startpunkter. Når du bytter kanal eller hopper i en DVD-film, må dekodingen starte med et I-bilde. Derfor er normalt hvert tolvte bilde et I-bilde. Hvis det er mye bevegelser i videoen, blir ofte B-bildene droppet.
Kraftkrevende
For å komprimere video trengs det både datakraft og god programvare. Jo mer det finnes av begge deler, desto bedre er det. Den høyeste kompresjonen oppnås når det er mulig å bruke lang tid og masse prosessorkraft for å få et optimalt resultat. Det gjør at DVD-er kan holde høy kvalitet selv på lave bitrater.
Å få klemt tre og en halv time av Ringenes Herre inn på en enkel DVD med 9,4 GB plass er nesten utrolig når kvaliteten tas i betraktning.
Vanskelig videokonferanse
Direktesendt TV og videokonferanse har ikke denne fordelen og må klare seg uten at koderen kan gå frem og tilbake mellom bildene for å optimalisere kompresjonen. En annen meget viktig fordel for DVD-koding er at man kan bruke så mange bit man trenger der det er stor bevegelse, for så å spare bit når bildet kommer til ro. Dette er ikke mulig for TV der man har en gitt kanal, f.eks. 5 Mb/s. Det setter begrensninger selv der man har store bevegelser.


Å pakke ut komprimert video er en mye mindre kraftkrevende prosess. Det er ikke lenge siden det tok all prosessorkapasiteten i en PC å dekode DVD selv om det er barnemat for dagens utgaver. Når HD-TV-signaler i Mpeg 4 skal dekodes, vil det kreve betydelig datakraft.
På vanlig DV-videobånd komprimeres bilde for bilde omtrent som i stillbildekameraer. De har en høyere bitrate på 25 Mbit/s, men det gjør det mye enklere å redigere videoen uten at den må dekodes og rekodes slik som med Mpeg. De siste årene har videokameraer med mini-DVD-er blitt populære, men de har betydelig mindre lagringskapasitet enn båndkassetten. Derfor har de kraftigere prosessorer som kan Mpeg-komprimere videoen i flere ulike kvalitetstrinn til en mye lavere bitrate.
Moderne stillbildekameraer har også fått prosessorkapasitet nok til å komprimere video i Mpeg 4.
Historien
Arbeidet med den første varianten, Mpeg 1 (Motion Picture Experts Group), begynte i 1988, og standarden ble tatt i bruk i 1993. Virkemåten er i store trekk den samme som vi bruker i mer avanserte Mpeg-varianter i dag, men i Mpeg 1 er bildeoppløsningen begrenset til 352 X 288 punkter. Mpeg 1 har en bitrate på rundt 1,5 Mbit/s som gir en kvalitet av VHS-typen.
I slutten av 1994 kom Mpeg 2 og ble formatet for DVD-er og digitalt fjernsyn. Her er oppløsningen variabel, men vanligvis 720 ganger 576 i PAL-format (europeisk TV).
I dag er det Mpeg 4 som gjelder, og mer spesifikt lag 10 av denne standardsamlingen. Den kompresjonsstandarden kjennes også som H.264, eller AVC for Advanced Video Coding. Mpeg 4 er et betydelig fremskritt innen videokompresjon og kan spare mellom 20 til 50 prosent av bitraten i forhold til Mpeg 2. Selv om det sendes HD-TV på Mpeg 2, er det Mpeg 4 som er fremtiden for høyoppløselig fjernsyn.
Mpeg 4 er mer effektiv fordi den benytter mer avanserte algoritmer som også krever betydelig mer prosessorkraft både til kodingen og dekodingen.
Microsoft prøver også å få fotfeste i videoverdenen med sin WMV-variant. Den kan sammenliknes med Mpeg 4 lag 10 i kvalitet.



