
På få år er søketeknologi blitt allemannseie. I tillegg til bokmerker er søkemotorer blitt måten vi manøvrerer rundt i nettet på. Det ville vært nesten umulig å ta seg frem i milliarder av websider uten hjelp.
Men hva skjer når vi skriver inn et søkeord og trykker på søk? Mange tror at søkemotoren fyker ut i cyberspace og elegant kommer tilbake med resultatet. Slik er det selvfølgelig ikke. Dette er som Ingrid Espelid ville si i Fjernsynskjøkkenet: «Noe vi har gjort ferdig på førehand».
Innsamling
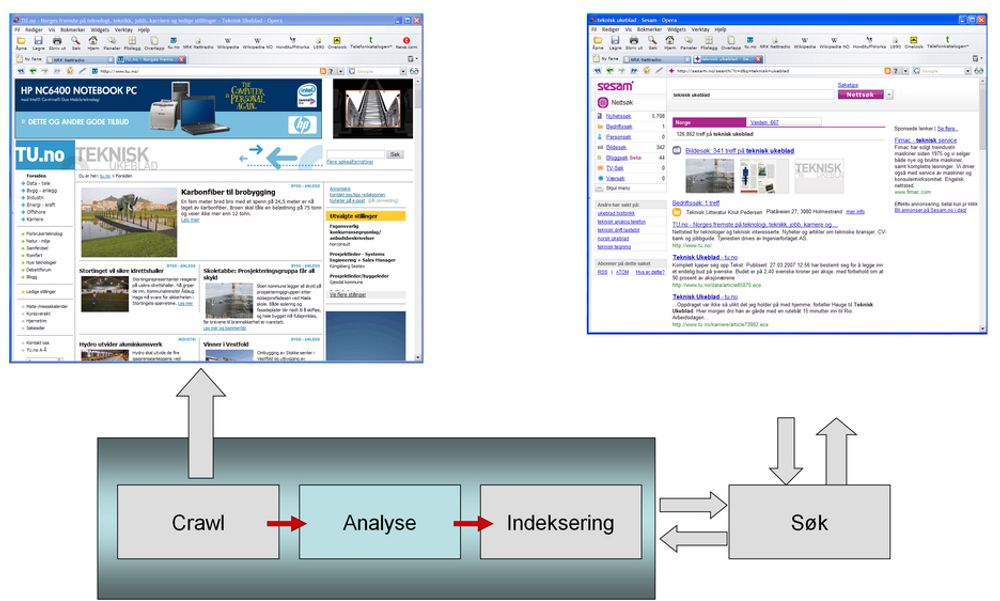
Skal en moderne søkemotor fungere, må innholdet den skal gi svar fra samles inn og bearbeides på forhånd. Når det er gjort, må innholdet knas av programvare og maskinvare på en måte som gir den som spør et fornuftig svar. Ingen liten jobb når det kan dreie seg om innholdet av hele den åpne delen av web-en på noen millisekunder.
Innholdet systematiseres av et program om kalles en crawler som kan gå på tusenvis av servere. Hvis det er internettsøk det dreier seg om, gis crawleren en del startsider, eller frøsider, som den starter med og så oppfører den seg omtrent som en svært nysgjerrig bruker. Den følger alle lenkene på siden videre.
På den måten vil crawlingen raskt spre seg ut i en slags vifteform. De ulike crawlerne samarbeider også og avstemmer resultatet så de unngår for mye dobbeltarbeid. På denne måten finner crawlingen alle sider på nettet som det refereres til fra andre sider.


På nytt og på nytt
Weben er i konstant endring. Nettaviser oppdateres kontinuerlig, mens andre sider står urørt i årevis. Utfordringen for søkemotorene er å være så oppdatert som mulig, men i snitt bruker de fra to til fire uker for hver gjennomgang av web-en. Likevel har de algoritmer som styrer oppdateringen slik at de viktigste nettstedene blir oppdatert mye oftere, kanskje flere ganger daglig.
På noen servere kan det ligge flere millioner websider, og de kan ha begrensninger for hvor ofte de kan spørres. Selv om de tillater en gang i sekundet, tar det tid å hente ut innholdet i alle sammen.
Analyse
Skal all informasjonen på nettet bli søkbar, må den gjennom en analyse og en indeksering. Det er i selve analysen den viktigste forskjellen mellom søkemotorene kommer frem. Analysen av nettsidene kan gjøres på mange måter, og formålet er å gi best mulig svar på de søkene som kommer. For eksempel blir nettsidene analysert lingvistisk gjennom flere algoritmer. På den måten kan de svare selv om spørsmålet bruker verbet i en annen bøyningsform enn det som finnes på siden, om spørsmålet eller siden har stavefeil, om det søkes på begreper osv.
Analysen kan også gjøres på tvers av flere dokumenter som til sammen kan gi et svar. Den kan ta for seg mønsteret i hvilke sider om lenker til andre sider fordi hvis mange lenker til en side, tyder det på høy kvalitet. Innholdsanalysen kan også gjøre at siden klassifiseres som populærvitenskapelig selv om ordet ikke er nevnt noe sted.


Når resultatene av alle analysene sammenstilles, er det grunnlaget for at alle sakene blir så presise og relevante som mulig. Alle søkemotorene har sine spesialiteter basert på analysene.
Indeksen
Når det hagler inn tusenvis av søk i sekundet som skal få svar fra et datagrunnlag som består av milliarder av dokumenter,trengs det datakraft. Mye datakraft.
For å løse kapasitetsutfordringen bygges resultatene fra analysene inn i en indeks som nesten er like enkel å slå opp i som en gigantisk telefonkatalog. En slik indeks kan fordeles over svært mange servere, og antallet kan økes når belastningen øker. Den kan også parallelliseres slik at søkene fordeles til parallelle kopier av indeksen. På den måten er det ingen øvre grense for hvor mange spørsmål en søkemotor kan besvare. Den kan skaleres lineært i det uendelige så lenge det er penger og kraft til å drive antallet servere. Google har flere hundre tusen servere, ifølge ryktene, og strømforbruket er som i en middels by.
Søkemotorer kan skalere fra én server opp til hundretusener som alle samarbeider om å betjene alle klientene som spør. For å utnytte datakraften best mulig benyttes algoritmer som fordeler belastningen på alle serverne optimalt mellom datatrafikken og alle dokumentoppslagene.
Mange bruksområder
Det er på internett søketeknologi er blitt mest kjent, men slik teknologi brukes på en lang rekke andre områder også. Innen bank, finans og mange andre bransjer brukes søketeknologi for å finne svar i enorme informasjonsmengder.
Her har norske FAST en sterk internasjonal posisjon, og de har kunder som har mange ganger mer informasjon enn det Google søker gjennom på internett.

